KNN (K-최근접 이웃, K-Nearest Neighbor)
분류 및 회귀에 적용 가능한 지도학습 모형.
분류 및 회귀에 적용 가능한 지도학습 모형. 대표적인 비모수적 모델(non-parametric model)이다. 새로운 데이터에 대해 가장 가까운 K개 이웃을 기반으로 분류 또는 회귀의 결과를 예측한다.
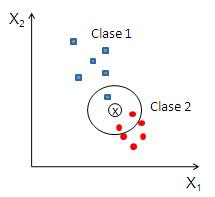
KNN의 분류
분류 문제의 기계학습 중에서 가장 간단한 방법이 KNN 알고리즘이다. KNN은 non-parametric model이기 때문에 파라미터를 변경해야 하는 다른 다른 기계학습 알고리즘과 달리 파라미터 튜닝을 하지 않아도 된다. 저장하고 있는 예제들에서 새로운 입력 x*과 가장 가까운 예제를 찾아내어, 그 정보를 기반으로 클래스 정보를 찾아준다. 이때, x*과 저장하고 있는 학습패턴 x 사이의 거리를 측정하는 기준이 필요하다. 입력이 연속이면 대개 유클리디안 거리를 사용하고, 입력이 이산이면 해밍 거리를 사용한다.
KNN의 분류 결과는 K개의 최근접 이웃들 중에서 가장 많이 존재하는 클래스가 된다. 즉, 다수결에 따라 K개 중 최빈갑승로 할당된다. 만약 k=1이면 가장 가까운 이웃이 속한 클래스가 새로운 x*의 클래스가 된다. 이같은 다수결 투표 방법은 클래스의 분포가 치우쳐있는 경우 클래스의 다수를 차지하는 쪽으로 결정이 기우는 단점을 드러낸다. 이럴 때는, x*과 k개의 이웃 정보 간의 거리 d를 고려하여 투표에 가중치를 적용할 수 있다. 즉, 가까운 이웃은 많은 투표를 행사하고 먼 이웃은 적은 투표를 행사하도록 투표에 가중치 1/d를 적용하면 된다.
How to KNN 분류
(1) 최근접 이웃의 수 K와 거리 측정 방법을 선택한다.
(2) 분류하려는 데이터에 대하여 K개의 최근접 이웃을 찾는다.
(3) 다수결 투표에 따라 분류 결과 클래스를 결정한다.
KNN의 회귀
KNN의 회귀 결과는 K개의 최근접 이웃들의 종속변수의 평균 값이 된다. 분류 문제에서와 마찬가지로 x*과 k개의 이웃 정보 간의 거리 d를 고려해 가중 평균을 적용할 수 있다. 즉, 가까운 이웃은 큰 가중치를 적용하고 먼 이웃은 적은 가중치를 행사하도록 가중치 1/d을 적용하면 된다.
How to KNN 회귀
(1) 최근접 이웃의 수 K와 거리 측정 방법을 선택한다.
(2) 예측하려는 데이터에 대하여 K개의 최근접 이웃을 찾는다.
(3) K개 최근접 이웃의 종속변수 평균 값으로 예측 결과 값을 결정한다.
KNN 특징
KNN은 lazyleaner다. 학습 데이터를 이용해 모형을 추정/구축하지 않는다. 대신 instance-based learning을 한다. 즉, 학습 데이터를 모두 기억하고 있다가 새로운 데이터가 들어오면 그때 이 학습 데이터를를 이용해 계산한다. (cf. model-based learning. Except KNN, all ML models that we learned are model-based learning)
KNN 파라미터 선정
KNN 알고리즘에서 최적의 k 선정은 데이터에 의해 좌우 된다. 일반적으로 k가 너무 작으면 데이터의 지역적 특성을 지나치게 반영해 과대적합이 될 수 있다. 반대로, k가 너무 크면 지나치게 일반화돼 과소적합이 될 수 있다.
차원의 저주
학습 데이터의 차원이 증가할수록, 특성 공간의 희소성이 증가하고 학습 성능이 낮아지는 이른바 '차원의 저주' 문제가 발생한다. 고차원으로 갈수록 전체 특성 공간에서 실제 데이터가 차지하는 비중(밀도)은 매우 낮아지는 것. 이 경우 정규화 또는 특징 추출 (feature extraction) 혹은 차원 축소(dimension reduction)을 해야 한다.
특징추출은 입력 데이터로부터 분류 혹은 회귀 목적과 관련된 특징을 추출하는 과정이다. 차원 축소는 고차원 데이터로부터 정보는 최대한 간직하면서 차원을 축소하는 과정으로 PCA(Principal Componant Analysis), LDA(Linear Discriminant Analysis) 기법이 주로 사용된다.

0 Comments
Post a Comment