< 백준 - 1157 > 단어공부
문제 :
알파벳 대소문자로 된 단어가 주어지면, 이 단어에서 가장 많이 사용된 알파벳이 무엇인지 알아내는 프로그램을 작성하시오. 단, 대문자와 소문자를 구분하지 않는다.
입력 :
첫째 줄에 알파벳 대소문자로 이루어진 단어가 주어진다. 주어지는 단어의 길이는 1,000,000을 넘지 않는다.
출력 :
첫째 줄에 이 단어에서 가장 많이 사용된 알파벳을 대문자로 출력한다. 단, 가장 많이 사용된 알파벳이 여러 개 존재하는 경우에는 '?' 를 출력한다.
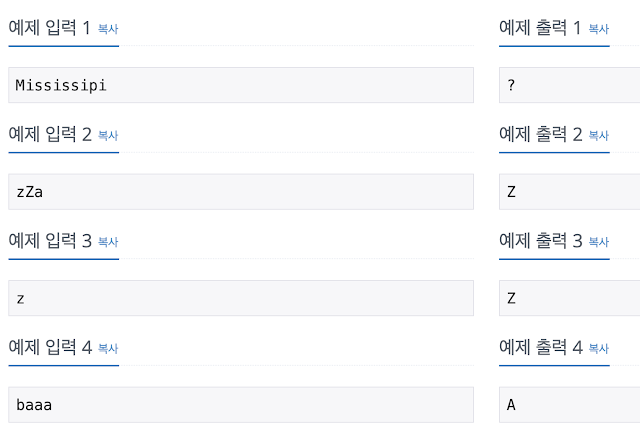
< 틀렸다는데 왜 틀렸는지 모르겠는 내 코드 >
위 코느는 문제에 나와있는 모든 예시들에 대해 옳은 출력을 돌려준다. 그런데 채점 결과는 '틀렸습니다'.
왜지...?!
일단, 위 코드의 흐름은 이렇다.
1. 소/대문자를 구분하지 않고, 마지막에 대문자로 출력해준다고 했으니 입력 받자마자 .upper( )을 써서 대문자로 통일시켜둔다.
2. 이렇게 입력받은 단어를 알파벳 한 자 한 자 나눠서 my_list 에 넣는다.
3. 가장 많이 사용된 단어를 판단하기 위해, set( ) 를 써서 중복되는 알파벳들을 제외하고, unique_list 만든다.
4. 딕셔너리를 하나 만들어 둔다.
6~7. unique_list에 든 원소들을 하나씩 꺼내와서 my_list에 해당 원소가 몇 개인지 세고, 그 값을 딕셔너리 d에 하나씩 추가한다.
만약 1번 줄에서 Mississipi를 입력받았다면, {'P': 1, 'M': 1, 'I': 4, 'S': 4} 와 같은 딕셔너리가 만들어진다.
9. 가장 많이 사용된 알파벳이 여러 개인지 판단하는 for 문이다. 만약 가장 많이 사용된 알파벳이 여러 개가 아니라면 d.value 리스트의 길이와 set(d.value) 길이가 같을 것이다.
길이가 같다면, 즉 사용된 빈도수가 높은 알파벳이 단 하나가 존재한다면, 해당 알파벳을 출력한다.
12~13. else 의 경우엔 '?'을 출력한다.
Mississipi로 다시 예를 들자면, Mississipi에서 가장 많이 사용된 알파벳은 이 각 4번씩 나온 'I', 'S'로 두 개다.
d.value = [1, 1, 4, 4]
set(d.value) = [1, 4]
따라서 len(d.value) != len(set(d.value))이고, '?'를 출력한다.
이 코드가 왜 틀렸는지 모르겠다...
< 정답 코드 >
결국 구글에서 위 코드를 찾았다.
collections 모듈을 사용한 코드니 이 모듈을 알아보자.
collections 모듈은 튜플, 딕셔너리에 대한 확장 데이터 구조를 제공하는 모듈이다. (?)

이 모듈 안에는 위와 같은 여러 함수가 존재한다.
문제를 푸는데 사용된 Counter 함수만 먼저 보자.
collections.Counter(word) 는 일련의 집합에서 각 원소의 출현 횟수를 세어 보여준다.
예를 들어
위 코드의 출력 결과는 Counter({'i' : 4, 's' : 4, 'M' : 1, 'p' : 1}) 이다.
 |
| 스트레스를 줄이기 위한 고양이 사진 / 출처 : 픽사베이 |
문제 :
알파벳 대소문자로 된 단어가 주어지면, 이 단어에서 가장 많이 사용된 알파벳이 무엇인지 알아내는 프로그램을 작성하시오. 단, 대문자와 소문자를 구분하지 않는다.
입력 :
첫째 줄에 알파벳 대소문자로 이루어진 단어가 주어진다. 주어지는 단어의 길이는 1,000,000을 넘지 않는다.
출력 :
첫째 줄에 이 단어에서 가장 많이 사용된 알파벳을 대문자로 출력한다. 단, 가장 많이 사용된 알파벳이 여러 개 존재하는 경우에는 '?' 를 출력한다.

< 틀렸다는데 왜 틀렸는지 모르겠는 내 코드 >
1 2 3 4 5 6 7 8 9 10 11 12 13 | w = input().upper() my_list = list(w) unique_list = list(set(my_list)) d = dict() for c in unique_list: d[c] = my_list.count(c) if len(set(d.values())) == len(d.values()): output = [charactor for charactor, cnt in d.items() if cnt == max(d.values())] print(output.pop()) else : print('?') |
위 코느는 문제에 나와있는 모든 예시들에 대해 옳은 출력을 돌려준다. 그런데 채점 결과는 '틀렸습니다'.
왜지...?!
일단, 위 코드의 흐름은 이렇다.
1. 소/대문자를 구분하지 않고, 마지막에 대문자로 출력해준다고 했으니 입력 받자마자 .upper( )을 써서 대문자로 통일시켜둔다.
2. 이렇게 입력받은 단어를 알파벳 한 자 한 자 나눠서 my_list 에 넣는다.
3. 가장 많이 사용된 단어를 판단하기 위해, set( ) 를 써서 중복되는 알파벳들을 제외하고, unique_list 만든다.
4. 딕셔너리를 하나 만들어 둔다.
6~7. unique_list에 든 원소들을 하나씩 꺼내와서 my_list에 해당 원소가 몇 개인지 세고, 그 값을 딕셔너리 d에 하나씩 추가한다.
만약 1번 줄에서 Mississipi를 입력받았다면, {'P': 1, 'M': 1, 'I': 4, 'S': 4} 와 같은 딕셔너리가 만들어진다.
9. 가장 많이 사용된 알파벳이 여러 개인지 판단하는 for 문이다. 만약 가장 많이 사용된 알파벳이 여러 개가 아니라면 d.value 리스트의 길이와 set(d.value) 길이가 같을 것이다.
길이가 같다면, 즉 사용된 빈도수가 높은 알파벳이 단 하나가 존재한다면, 해당 알파벳을 출력한다.
12~13. else 의 경우엔 '?'을 출력한다.
Mississipi로 다시 예를 들자면, Mississipi에서 가장 많이 사용된 알파벳은 이 각 4번씩 나온 'I', 'S'로 두 개다.
d.value = [1, 1, 4, 4]
set(d.value) = [1, 4]
따라서 len(d.value) != len(set(d.value))이고, '?'를 출력한다.
이 코드가 왜 틀렸는지 모르겠다...
< 정답 코드 >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | from collections import Counter word = input().upper() c = Counter(word) many = [] for k, v in c.items(): if v == max(c.values()): many.append(k) if len(many) > 1: break if len(many) == 1: print(many[0]) else: print('?') |
결국 구글에서 위 코드를 찾았다.
collections 모듈을 사용한 코드니 이 모듈을 알아보자.
collections 모듈은 튜플, 딕셔너리에 대한 확장 데이터 구조를 제공하는 모듈이다. (?)

이 모듈 안에는 위와 같은 여러 함수가 존재한다.
문제를 푸는데 사용된 Counter 함수만 먼저 보자.
collections.Counter(word) 는 일련의 집합에서 각 원소의 출현 횟수를 세어 보여준다.
예를 들어
1 2 3 4 5 | from collections import Counter word = 'Mississipi' Counter(word) print(a) |
위 코드의 출력 결과는 Counter({'i' : 4, 's' : 4, 'M' : 1, 'p' : 1}) 이다.
#%% from collections import Counter cnt = Counter() list = [1,2,3,4,1,2,6,7,3,8,1] Counter(list)
>> Counter({1: 3, 2: 2, 3: 2, 4: 1, 6: 1, 7: 1, 8: 1})
# The most_common() 함수 # The Counter() function returns a dictionary which is unordered.
# You can sort it according to the number of counts in each element using
# most_common() function. #%% list = [1,2,3,4,1,2,6,7,3,8,1] cnt = Counter(list) cnt #%% cnt.most_common()
>> [(1, 3), (2, 2), (3, 2), (4, 1), (6, 1), (7, 1), (8, 1)]

0 Comments
Post a Comment